Introduction
A leading content delivery network (CDN), CloudFront.net offers unparalleled opportunities when combined with the power of web scraping. This guide delves into this synergy and offers insights into maximizing efficiency, ensuring data accuracy, and navigating the domain responsibly.
CloudFront.net: A Content Delivery Giant
Amazon CloudFront, often referred to by its domain "CloudFront.net", is a content delivery network (CDN) service offered by Amazon Web Services (AWS).
A CDN is a system of distributed servers that deliver web content and applications to users based on their geographic location. It aims to provide high availability and performance by distributing the service spatially relative to end-users.
CloudFront integrates with other AWS to give developers and businesses an optimized way to distribute content to end-users with low latency and high data transfer speeds.
It works by storing copies of your content in multiple locations worldwide, known as edge locations. When a user requests content, CloudFront delivers it from the nearest edge location, ensuring the fastest possible load time.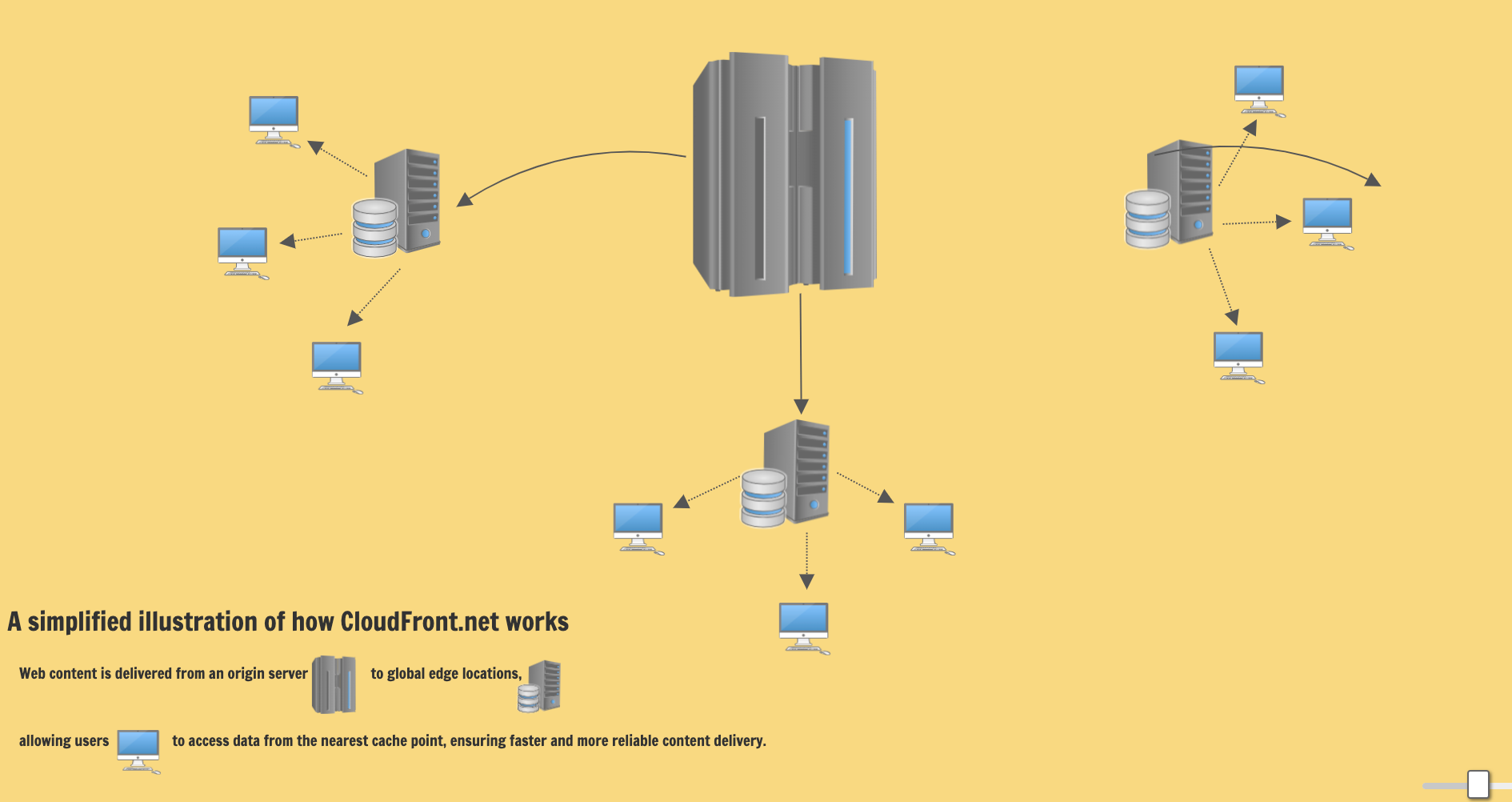
CloudFront's Key Features & Benefits
-
Global Reach. CloudFront has a vast network of edge locations around the world to reduce latency and ensure that content is delivered from the nearest point to the end-user.
-
Deep AWS Integration. CloudFront is integrated with AWS services like Amazon S3, Amazon EC2, Elastic Load Balancing, and Route 53, making it easier to use these services together.
-
Security. CloudFront offers multiple layers of security, including HTTPS support, AWS Shield for DDoS mitigation, and AWS WAF (Web Application Firewall) integration.
Photo from Vecteezy
-
Customization Options. Developers can customize content delivery and adapt the CDN to specific application requirements.
-
Cost-Effective. CloudFront uses a pay-as-you-go model, ensuring you only pay for the data you transfer without any upfront costs.
-
Dynamic and Static Content Delivery. While many CDNs specialize in static content delivery, CloudFront supports both static and dynamic content.
-
Developer-Friendly. With SDKs and a well-documented API, developers can easily integrate and manage CloudFront distributions.
-
Real-time Metrics and Logging. CloudFront provides detailed metrics and logs, allowing for in-depth analysis and monitoring of content delivery.
Understanding Web Scraping and Data Extraction
Web scraping is the process of collecting data from a website.
It involves making HTTP requests to web pages, retrieving the HTML content, and then parsing and extracting the desired information.
Photo from Vecteezy
Unlike manually copying data from a website, web scraping automates this process, allowing for the extraction of vast amounts of data in a relatively short amount of time.
The process typically involves:
- Sending a Request. A scraper sends an HTTP request to the target website.
- Receiving the Response. The website responds with HTML content.
- Parsing the Content. The scraper processes the HTML using parsing techniques to identify specific data structures.
- Data Extraction. Once identified, the desired data is extracted from the parsed content.
- Data Storage. The extracted data is then stored in a structured format, often in databases or spreadsheets.
The Impact of Web Scraping Across Industries
Web scraping has a myriad of applications across various industries:
-
E-commerce. Retailers scrape competitor websites to monitor prices and product offerings.
-
Real Estate. Property websites are scraped to gather data on property listings, prices, and market trends.
-
Recruitment. Job portals are scraped to find job listings and analyze market demands for specific skills.
Photo from Vecteezy
-
Finance. Financial institutions scrape stock market websites to track stock prices, news, and market sentiments.
-
Research. Academics and researchers scrape the web for data collection in various fields.
-
News & Media. Aggregators scrape news sites to curate content from different sources.
-
Travel. Travel agencies scrape airline and hotel websites for price comparison and offer generation.
Web Scraping Tools & Techniques
There are numerous tools and techniques available for web scraping, ranging from simple browser extensions to complex software.
1. Headless Browsers
Photo from Vecteezy
Headless browsers play a significant role in modern web scraping, especially when dealing with platforms like CloudFront.net. Here's why they are often essential for scraping CloudFront.net:
-
Dynamic Content Loading. Many websites, including those hosted on CloudFront.net, use JavaScript to load content dynamically.
Traditional scraping tools fetch the initial HTML of a page, which might not contain all the data if the content is loaded asynchronously via JavaScript.
Headless browsers can execute JavaScript, allowing scrapers to access dynamically loaded content.
-
Simulating Real User Behavior. Headless browsers can mimic actual user interactions, such as scrolling, clicking buttons, or filling out forms.
This capability is crucial when the data you want to scrape is behind some user interaction.
-
Rendering Web Pages. Some content on CloudFront.net might be rendered using web frameworks like React, Angular, or Vue.js. These frameworks often require a browser environment to correctly render the page's content.
Headless browsers can render these pages, ensuring that the scraper sees the page the same way a human user would.
-
Cookies and Sessions. Headless browsers can manage cookies and sessions, which might be necessary for accessing certain content on CloudFront.net, especially if it requires user authentication or session tracking.
-
Debugging and Development. Headless browsers often come with developer tools that allow for debugging and testing the scraping scripts.
This feature is invaluable when developing and refining scraping strategies for complex websites.
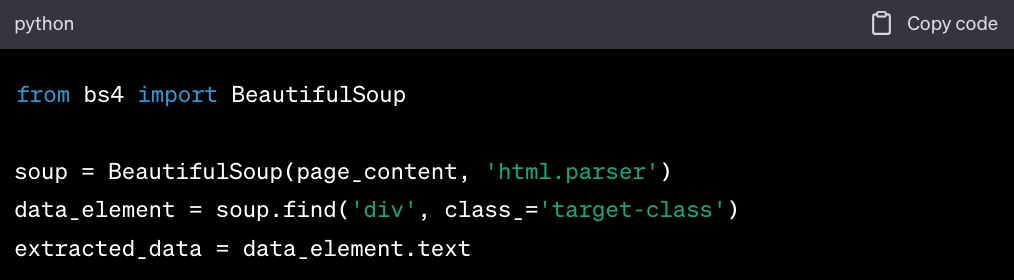
2. Python & BeautifulSoup
Python is a versatile programming language widely used for web scraping, allowing you to write lines of code for your needs. It has simple yet extensive libraries, one of which is BeautifulSoup.
Photo from Pexels
BeautifulSoup is a Python library that lets you collect information from web pages. It creates a parse tree from the page source code, which can be used to extract data in a hierarchical and more readable manner.
Combined with Python's `requests` library to fetch web pages, BeautifulSoup makes the process of web scraping straightforward and efficient.
Key Features of BeautifulSoup
- Easy Parsing. Can parse both well-formed and malformed HTML or XML files.
- Find Methods. Provides methods like `find()`, `find_all()`, and `select()` to navigate and search the parse tree.
- Tag Manipulation. Allows for easy manipulation of tags and attributes.
- Encoding. Automatically converts incoming documents to Unicode and outgoing documents to UTF-8 encoding.
3. Proxies for Enhanced Web Scraping
Proxies act as intermediaries between a user and the internet. They play a pivotal role in web scraping for several reasons:
-
Anonymity. Web scraping can lead to IP bans if websites detect unusual traffic from a single IP address.
Proxies mask the scraper's real IP, ensuring anonymity and reducing the risk of detection and bans.
-
Geo-Targeting. Some websites display different content based on the user's geographical location.
Proxies allow scrapers to access content from specific regions by using IP addresses from those areas.
-
Rate Limiting. Websites often have rate limits to prevent overload. By rotating through multiple proxy IP addresses, scrapers can make more requests to a website without hitting rate limits.
Photo from Pexels
-
Parallel Scraping. Using multiple proxies allows for concurrent requests, speeding up the data extraction process, especially for large-scale scraping tasks.
-
Reduced Blocking. Websites use various anti-scraping measures. Proxies, especially when rotated frequently, can help bypass these measures, ensuring uninterrupted scraping.
Why Scrape CloudFront.net?
Here are some real-world applications for data that can be gathered from CloudFront.net (or websites delivered via CloudFront):
-
Competitive Analysis. Businesses might want to understand the content, structure, or assets of a competitor's website delivered through CloudFront to gauge their online strategies, offerings, or digital presence.
-
Content Aggregation. Aggregators, like news or price comparison platforms, might scrape sites delivered via CloudFront to collect and present consolidated information to their users, offering value through comprehensive data.
-
Research and Academic Purposes. Researchers or students might scrape websites on CloudFront to gather data for academic projects, studies, or papers, aiming to analyze trends, patterns, or phenomena.
[Photo](https://Photo by Vlada Karpovich https) from Pexels
-
SEO Analysis. SEO professionals might scrape sites delivered through CloudFront to understand their on-page SEO strategies, backlink profiles, or content structures, aiding in refining their own or their clients' SEO tactics.
-
Content Monitoring. Brands or individuals might want to monitor specific websites on CloudFront for mentions, reviews, or updates, enabling them to stay informed and react promptly to new content.
-
Backup and Archival. Some entities might want to create backups of their own web content delivered via CloudFront, ensuring they have historical versions or archives for future reference.
-
Market Analysis. E-commerce businesses or market analysts might scrape product listings, reviews, or pricing data from sites on CloudFront to understand market trends, consumer preferences, or pricing strategies.
It's essential to note that while these use cases present legitimate reasons for web scraping, always ensure that you do ethical scraping especially when dealing with sites delivered via robust CDNs like CloudFront.
How to Scrape CloudFront.net
- Identify the Target URL. Determine the specific CloudFront.net URL you wish to scrape.

- Inspect the Web Page. Use browser developer tools to inspect the page structure and identify the data you want to extract.

- Write the Scraping Script. Utilize Python libraries to write a script that fetches and parses the web page.
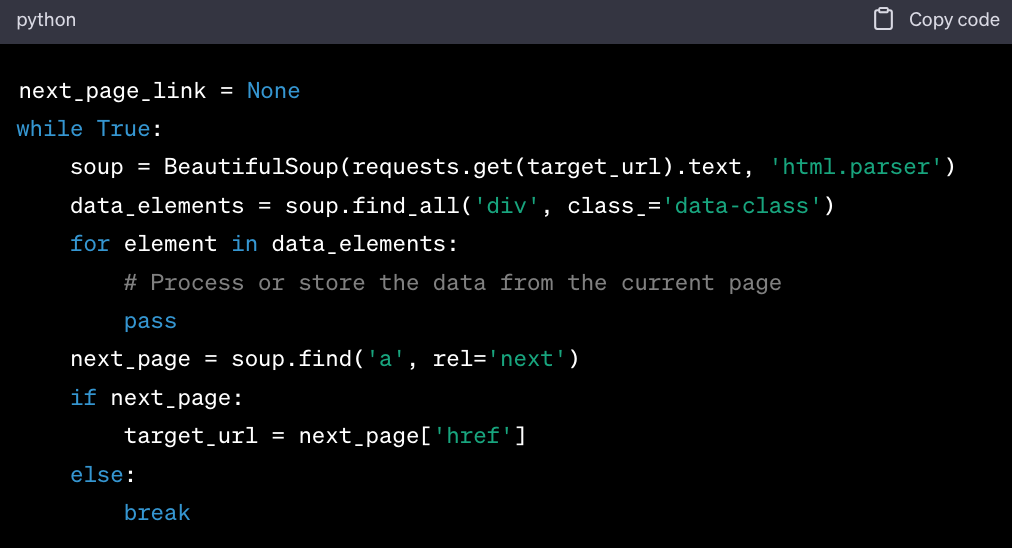
- Handle Pagination. If the content spans multiple pages, ensure your script can navigate and scrape data from all pages. (Assuming each page has a "Next" button linking to the next page.)
- Store the Data. Save the scraped data in a structured format like CSV file, JSON, or a database.

- Respect
robots.txt: Always check and respect the robots.txtfile of CloudFront.net to ensure you're not violating any scraping rules. 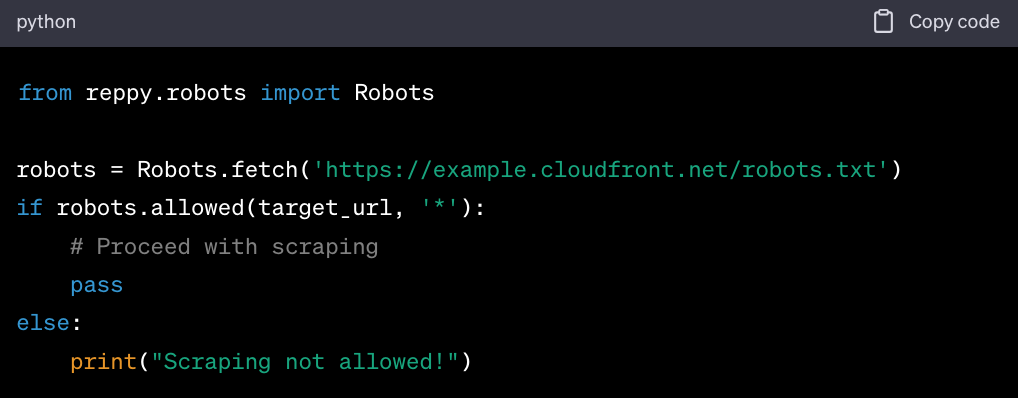
Navigating the Legal Landscape of Scraping CloudFront.net
Web scraping, especially platforms like CloudFront.net, requires a keen understanding of the legal intricacies involvedm, such as
-
Terms of Service (ToS). Before scraping CloudFront.net or any other site, always review its ToS.
Always review the AWS Service Terms before initiating any scraping activity on CloudFront.net or other AWS services. Ignoring these terms can lead to legal repercussions.
-
Copyright Laws. Data on CloudFront.net, even if publicly accessible, may be protected by copyright.
Ensure that the extracted data is used in a manner that doesn't infringe on these laws.
Photo from Pexels
-
Data Protection Regulations. Regulations like GDPR and CCPA emphasize user privacy.
When scraping personal data from CloudFront.net, ensure compliance with these laws, including secure storage and necessary permissions.
-
Computer Fraud and Abuse Act (CFAA). This U.S. act criminalizes unauthorized access to computer systems.
Ensure your scraping activities on CloudFront.net don't violate its ToS to avoid conflicts with the CFAA.
Respecting Digital Boundaries on CloudFront.net
Ethical web scraping is about respecting the digital space of platforms like CloudFront.net:
-
Rate Limiting. Avoid overwhelming CloudFront.net by sending too many requests in a short time.
Adhere to any rate limits and space out your scraping activities.
-
Sensitive Information. CloudFront.net may host personal or sensitive data. Prioritize user privacy and avoid malicious web scraping.
-
Acknowledge Source. If using data from CloudFront.net for research or other purposes, always credit the platform as the source.
-
Seek Permission. If unsure about scraping CloudFront.net, it's best to seek permission from the platform's administrators.
Overcoming Anti-Scraping Measures on CloudFront.net
CloudFront.net, like many platforms, may have measures for deterring scrapers:
- User-Agents. CloudFront.net might block known scraper user-agents. Rotate user-agents or mimic a genuine browser to bypass this.
- CAPTCHAs. CloudFront.net may use CAPTCHAs to verify human users. While tools exist to bypass them, frequent challenges can lead to IP bans.
- IP Bans. If CloudFront.net detects unusual activity, it might block the IP. Use proxies r esponsibly to rotate IPs and continue scraping.
- Honeypots. Be cautious of honeypot traps on CloudFront.net—fake data points set up to detect scrapers.
Optimizing CloudFront.net Scraping tasks with Geonode Residential Proxies
Integrating Geonode proxies with web scraping tools and scripts can significantly enhance the scraping process, especially when targeting robust platforms like CloudFront.net.

Geonode has made a significant as a proxy service provider thanks to its wide range of standout features.
Acclaimed for its reliable proxy network that ensures minimal downtime and consistent performance, Geonode boasts of a broad coverage, backed by a vast number of IP addresses spanning multiple countries.
Moreover, Geonode offers swift response times due to its robust infrastructure, a crucial factor for efficient web scraping. It provides secure connections and caters to varied web scraping needs, guaranteeing data privacy and protection against potential threats.
People Also Ask
How does CloudFront.net enhance content delivery?
CloudFront.net is a content delivery network (CDN) service provided by Amazon Web Services (AWS).
In simple terms, a CDN is like a network of fast delivery couriers spread across the globe, ensuring that online content reaches users quickly and efficiently. Here's how it works:
-
Global Distribution. CloudFront has numerous data centers, known as edge locations, spread worldwide.
When a user requests content, it's delivered from the nearest edge location, ensuring minimal delay or latency.
-
Integrated with AWS. As part of the AWS ecosystem, CloudFront seamlessly integrates with other AWS services.
If your website or application is hosted on AWS, using CloudFront can make content delivery even more efficient.
-
Dynamic and Static Content. While some CDNs are best suited for delivering static content (like images or stylesheets), CloudFront is adept at delivering both static and dynamic content (like user-specific web pages).
-
Security. CloudFront offers robust security features, including HTTPS for secure data transfer, protection against DDoS attacks, and integration with AWS's Web Application Firewall.
-
Cost-Effective. With its pay-as-you-go model, users only pay for the content they deliver, making it a cost-effective solution for businesses of all sizes.
In essence, CloudFront.net ensures that your online content reaches your users quickly, securely, and efficiently, no matter where they are in the world.
Why are proxies like Geonode crucial for web scraping?
Web scraping involves gathering different kinds of data from websites. However, this process isn't always straightforward.
Websites may have measures to block or limit automated access. This is where proxies, especially reliable ones like Geonode, come into play:
-
Bypassing Restrictions. CloudFront.net, being a part of the AWS suite, has robust security measures.
Geonode proxies can help bypass IP-based restrictions and access data without triggering alarms.
-
Load Balancing. When scraping large datasets from CloudFront.net, Geonode proxies can distribute the requests, ensuring efficient load balancing and faster data retrieval.
-
Fresh Data Access. CloudFront.net might serve cached content based on the geographical location of the request.
Geonode's wide range of IP addresses ensures access to fresh, real-time data.
-
Error Handling. In case of blocks or captchas, scripts integrated with Geonode can automatically switch to another proxy, ensuring uninterrupted scraping.
-
Rate Limit Avoidance. CloudFront has limits on the number of requests from a single IP in a given time.
By rotating through Geonode proxies, scrapers can make more frequent requests without being blocked.
-
Reliability. Not all proxies are created equal. Geonode is known for its stable and high-speed proxies, ensuring efficient and uninterrupted scraping.
-
Security. Using Geonode proxies ensures a secure connection, protecting the scraper from potential threats and prying eyes.
For anyone serious about web scraping, reliable proxies like Geonode are not just beneficial; they're essential.
Is web scraping legal?
In the U.S., the legality of web scraping has been a topic of debate and has been addressed in various court cases.
One of the most cited cases is hiQ Labs, Inc. v. LinkedIn Corp., where the Ninth Circuit Court of Appeals held that scraping publicly accessible websites likely does not violate the CFAA.
The court ruled in favor of hiQ, a company that scraped LinkedIn's publicly available data.
The court's decision was based on the interpretation that the CFAA targets breaches of computer access restrictions and not the misuse of data by parties who had authorized access.
While web scraping isn't inherently illegal, it's crucial to approach it responsibly.
Always respect a website's ToS, be mindful of copyright and data protection laws, and when in doubt, seek legal counsel.
Wrapping Up
The interplay between CloudFront.net, web scraping, and Geonode proxies paints a compelling picture of efficiency, innovation, and responsible data acquisition.
With its global reach, CloudFront.net facilitates swift content delivery, and promotes a seamless user experience.
Web scraping, meanwhile, unlocks significant insights, fueling research and innovation when used ethically.
Geonode proxies complement this process, enabling anonymous web navigation, bypassing geo-restrictions, and supporting steady data flow.
But as we harness the combined capabilities of CloudFront.net, web scraping, and Geonode proxies, it's imperative to prioritize ethical practices.
Photo from Vecteezy
Respecting digital boundaries, adhering to legal guidelines, and ensuring the privacy and rights of online entities should be at the forefront of all endeavors.
Let's all commit to ethical practices and a continuous pursuit of knowledge. The digital realm is ever-evolving, and by treading responsibly and staying informed, we can ensure that our actions benefit not just us, but the broader online community.
.
