Are you tired of manually searching for event tickets on SeatGeek? Wish there was a way to streamline the process and save time?
With a vast selection of tickets available, it can be overwhelming to manually search for the best deals. However, by using web scraping techniques, you can automate the process and gather all the ticket information you need in a matter of minutes.
Web scraping is a valuable skill that allows you to extract data from websites and use it for various purposes. By scraping SeatGeek.com, you can access up-to-date ticket prices, availability, and other important details.
Whether you're a frequent concert-goer or a ticket reseller, learning how to scrape SeatGeek.com will give you a competitive edge and ensure you never miss out on the best deals again.
What is SeatGeek?
SeatGeek.com is a popular online ticket marketplace that allows users to buy and sell tickets for various events such as concerts, movies, sports games, and theater shows.
It provides a platform for individuals to find the best deals and compare prices from different sellers.
SeatGeek also offers features interactive seating maps, real-time ticket listings, and a mobile app for easy access on the go.
The website has gained popularity for its user-friendly interface and reliable ticketing services, making it a go-to platform for many event-goers.
Why is SeatGeek so popular?
SeatGeek, one of the biggest event aggregator websites for both live and online events, differentiates itself from other ticket websites by offering a user-friendly interface, transparent pricing, and a "Deal Score" system that evaluates ticket deals based on price and seat quality.
 Photo from Pexels
Photo from Pexels
Compared to other ticket platforms like Ticketmaster, StubHub, and Vivid Seats, SeatGeek often provides a more visual seat selection process with interactive venue maps and consolidates listings from various sources, giving users a broader view of available tickets.
However, while Ticketmaster is primarily a primary ticket seller (direct from the event organizer), SeatGeek, StubHub, and Vivid Seats operate mainly in the secondary market, where tickets are resold, often at prices determined by demand.
Why Scrape SeatGeek?
SeatGeek is a prominent online platform that aggregates and lists tickets for a myriad of events. As such, it holds a wealth of information that can be of interest to various stakeholders for different reasons, such as:
• Market Research and Analysis. By scraping SeatGeek, businesses and analysts can gather data on ticket pricing trends, event popularity, venue capacities, and more. This data can provide insights into the entertainment industry's dynamics, helping businesses make informed decisions.
• Competitive Analysis. Competing platforms or event organizers might want to understand SeatGeek's ticket pricing, event listings, and other offerings to position their services better or to identify potential partnership opportunities.
 Photo from Pexels
Photo from Pexels
• Event Discovery. Content aggregators or event recommendation platform might scrape SeatGeek and gain access to event details so they can provide their users with a comprehensive list of upcoming activities in a particular region.
• Price Monitoring. By regularly scraping SeatGeek, one can see the original price and set the purchase price for specific events. This can be valuable for ticket resellers, event organizers, or even consumers looking for affordable prices and the best deals.
• Data Integration. Businesses that operate in the event or entertainment sector might want to integrate SeatGeek's data into their platforms to provide enhanced services to their users, such as event recommendations or travel package suggestions based on events.
• Academic Research. Researchers studying the entertainment industry, consumer behavior, or event management might scrape SeatGeek to gather data for their studies.
• Notification Services. Developers can create services that notify users when tickets for specific events or within a particular price range become available. This is especially useful for high-demand events that sell out quickly.
• Trend Prediction. By analyzing historical data from SeatGeek, one can potentially predict future trends in the entertainment industry, such as which types of events are gaining or losing popularity.
The reasons for scraping SeatGeek are diverse and span across various sectors and interests. Whether for business intelligence, academic research, or personal use, the data available on SeatGeek offers valuable insights into the world of events and entertainment.
Understanding the Structure of SeatGeek's Website
SeatGeek is an online platform that offers a secondary marketplace for users to buy and sell tickets to various events. To effectively scrape data from SeatGeek, it's essential to understand the structure of the website and the elements that can be extracted.
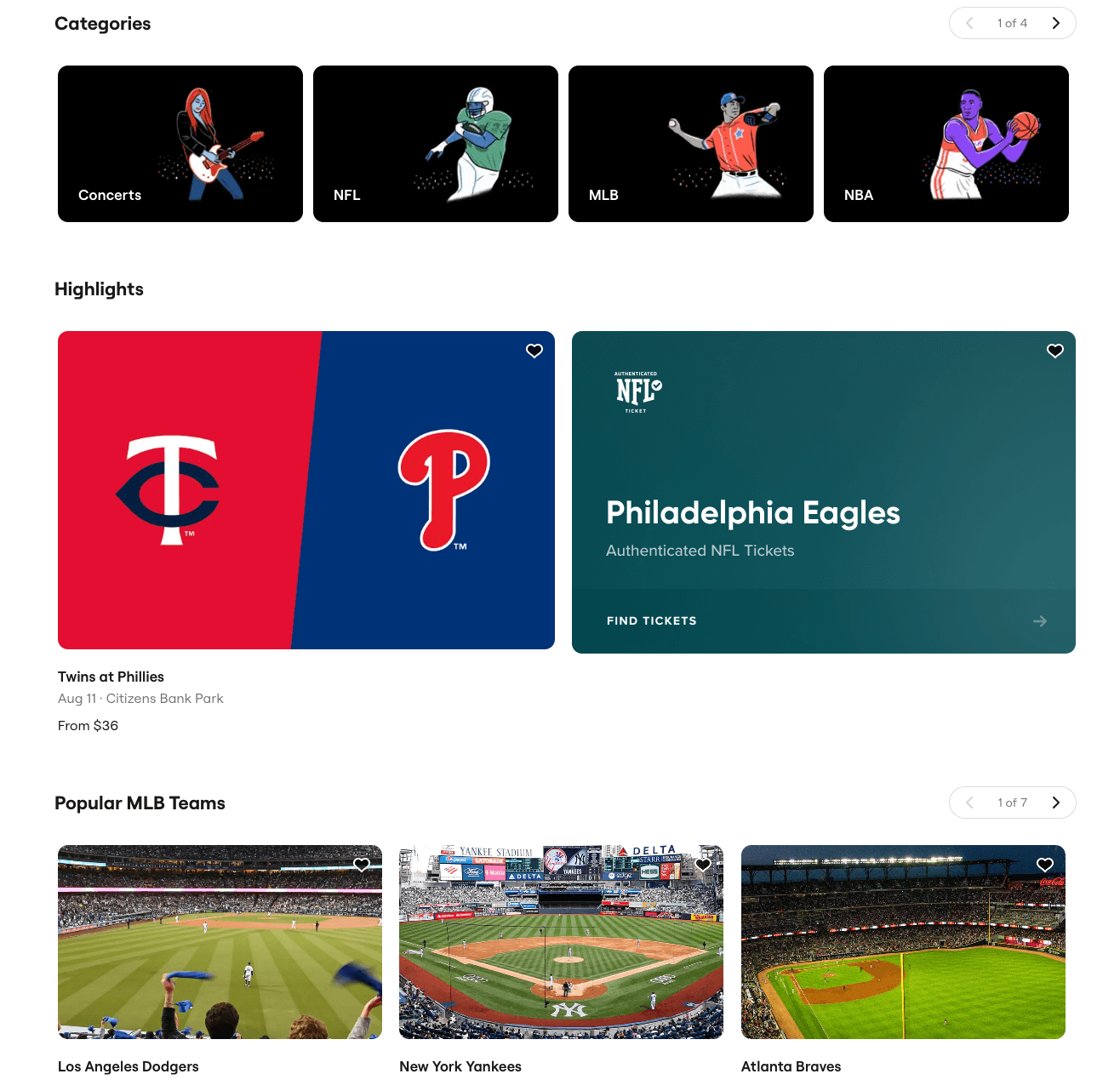
Event Details
Event Name. The name or title of the event.
Event Description. A brief description or summary of the event; can also include quick event details.
Event Category. The type or category of the event (e.g., concert, play, game).
Event Schedule. Event dates and times associated with the event.
Accessible Amenities. Facilities or services available at the event venue.
Ticket Details
Ticket Pricing. This includes both the opening and closing sales prices.
Original Ticket Price. The initial price of the ticket when first released.
Ticket Availability. Information on the number of tickets available or sold out.
Venue and Location Details
Address. The full address of the event venue.
City. The city where the event is taking place.
Zip Code. Postal code of the event location.
State. The state or region of the event location.
Locations. Specific locations or areas within the venue.

Other Relevant Details
Attendees. Information about people attending the event, online event planners, and more.
Speakers. Details about speakers or performers at the event.
Organizer’s Profile. Information about the event's organizers.
Booth Details. Information about stalls or booths at the event.
Exhibitors. Details about exhibitors present at the event.
Contact Details. Contact information related to the event or its organizers.
Reviews. Feedback or reviews related to the event or the venue.
Seller Information. Name and contact details, payment details, physical and email address, as well as seller feedback and rating.
Restrictions on Scraping SeatGeek
While SeatGeek offers a plethora of data that can be valuable for various purposes, it's essential to approach web scraping with caution, respecting the platform's terms of use and any legal implications.
Additionally, this is the SeatGeek Legal Department's position on web scraping, according to its Terms of Use:
• Public search engines are allowed to use spiders to create searchable indices of the materials but not caches or archives of such materials.
• The information, content, and services available on SeatGeek are protected by copyright laws. Users are granted limited rights to use SeatGeek's properties, subject to certain restrictions.
 Photo from Vecteezy
Photo from Vecteezy
• Users cannot use any manual or automated software, devices, or other processes to "scrape" or download data from any web pages on SeatGeek. This includes spiders, robots, scrapers, crawlers, avatars, data mining tools, etc.
• Users cannot license, sell, rent, or otherwise commercially exploit SeatGeek's properties. They also cannot modify, translate, adapt, or make derivative works of any part of SeatGeek's properties.
Web scraping, while useful, comes with ethical and legal considerations. It's crucial to respect the terms of service of SeatGeek to ensure that the scraping does not harm or overload the website.
Additionally, the scraped data should be used responsibly, respecting any copyrights or proprietary rights associated with the content.
Tools for Scraping SeatGeek
There are several methods and tools that can be used to scrape data from SeatGeek's website. Here's a breakdown of the different ways SeatGeek.com can be scraped:
 Photo from Vecteezy
Photo from Vecteezy
1. Specialized Web Scraping Services
There are specialized web scraping services that offer SeatGeek data scraping services. These services have developed specific scrapers tailored to extract data from SeatGeek and other similar event sites.
2. Custom Scripts
Available on GitHub, Scrapetix is a script designed to scrape sports ticket deals from SeatGeek. It offers features like customized ticket scraping based on your favorite team, price range, and more. It also supports recurring scraping with email notifications for new deals. The script uses PhantomJS to run the scraping script.
3. Web Scraping Tools
• PhantomJS: This is a headless browser used for web scraping. It can render web pages and execute JavaScript, making it suitable for scraping dynamic websites like SeatGeek that rely heavily on JavaScript for content rendering.
• Node.js: This is a JavaScript runtime that can be used to write server-side scripts. Combined with libraries like Axios for making HTTP requests and Cheerio for parsing HTML, Node.js can be a powerful tool for web scraping.
• Other Tools: There are many other web scraping tools and libraries available, such as Beautiful Soup, Scrapy, Puppeteer, and Selenium. Depending on the structure and complexity of the website, one might choose a specific tool over another.
4. Headless Browsers
Websites like SeatGeek might load content dynamically using JavaScript. Traditional scraping tools that only fetch the HTML might not be able to capture this dynamic content. In such cases, using headless browsers like PhantomJS, Puppeteer, or Selenium, which can render and execute JavaScript, becomes essential.
Step-by-step Guide to Scraping SeatGeek with Scrapetix
The Scrapetix script provides a framework for scraping SeatGeek. It allows for customized ticket scraping based on user preferences such as favorite team and price range. The script also supports recurring scraping with email notifications for new deals. With Scrapetix, you can edit the configuration file on-the-fly without restarting the script.
1. Prerequisites
Before you begin, ensure you have the following:
• A working installation of Node.js.
• Git installed on your system.
2. Clone the Repository
Clone the Scrapetix repository from GitHub to your local machine.

3. Navigate to the Directory
Change your current directory to the cloned repository.

4. Install PhantomJS
Install PhantomJS using the appropriate method for your operating system. For example, on macOS, you can use Homebrew.

5. Install Required Packages
Install the necessary Node.js packages for the script.

6. Configuration
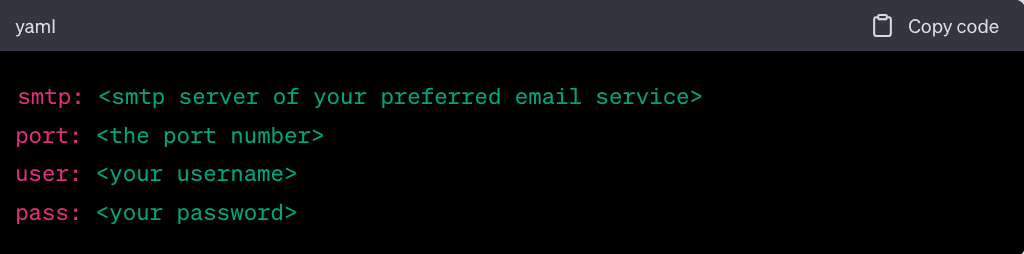
Email Configuration. To receive deal alerts via email, create a private.yml file in the root directory of the project and add your email information.
• Customized Configuration. Modify the config.yml file to set your preferences.
Set your email.

Choose your favorite team's URL. For example, for Pittsburgh Penguins.

Set the location based on the team's name.

Adjust the interval between two consecutive scrapes.

Set your filtering criteria for the tickets you want to scrape.

7. Run the Script
Use PhantomJS to run the scraping script.

8. Monitor for Alerts
If the script finds ticket deals that match your criteria, it will send email alerts to the specified email address.
9. Stopping the Script
To stop the script, simply press CTRL + C in the terminal.
10. Data Analysis
The script will generate data based on your criteria. You can analyze this data to find the best ticket deals for your preferences.
11. Storing and Analyzing the Scraped Data
Once the data is scraped, it can be stored in a CSV file, database, or other storage systems for further analysis. The data can be processed to remove noise and ensure that only real-time, relevant information is retained.
Tips and Tricks for Successful Scraping on SeatGeek
 Photo from Vecteezy
Photo from Vecteezy
• Always check SeatGeek's robots.txt file to understand which parts of the site can be scraped.
• From time to time, appropriate intervals between requests to avoid overloading the website or getting blocked.
• Regularly update the scraping script to adapt to any changes in the website's structure.
• Use filters and criteria to ensure that only relevant data is scraped.
• Avoid restrictions by rotating user agents and your IP address. Geonode offers unlimited and pay-as-you-go residential proxies that you can use for distributing requests.
Ready for Web Scraping SeatGeek?
The vast amount of data available on event ticket search engines like SeatGeek offers a treasure trove of insights for various stakeholders, from event enthusiasts to market analysts.
Web scraping, when done ethically and responsibly, can unlock these insights and provide a competitive edge in the ever-evolving world of events and entertainment.
With the right tools and techniques, anyone can harness this data for valuable purposes. However, always remember to approach web scraping with respect to services, and the platform's guidelines and legal considerations. As the landscape of online data continues to grow, so too does the potential for innovation and discovery.
