Picture this: With a few lines of code, you unlock a wealth of data from Subito.it, Italy's go-to online marketplace.
This isn't just a neat tech hack; it's a revolutionary move for anyone serious about data-driven decisions.
Whether you're keen on understanding consumer behavior, staying ahead with dynamic pricing, or outsmarting the competition, web scraping Subito.it is your golden ticket.
Dive into this guide to learn how you can elevate your business strategy by tapping into the data-rich world of Subito.it.
What is Subito.it?
Subito.it is an Italian online platform where users can buy and sell new and used items.
The website offers a wide range of categories, including motors, market, real estate, and jobs.
Users can post local advertisements for cars, houses, electronics, furniture, pets, and much more.
The platform also provides various features to make transactions safer and more convenient, such as tracked shipping and secure payment options.
Why Scrape Subito.it?
Web scraping has become an essential tool in the modern business landscape, and Subito.it, as one of Italy's largest online marketplaces, offers a wealth of data that can be invaluable for various applications.
Importance of Subito.it Data in eCommerce
Subito.it is not just another online marketplace; it's a data goldmine for anyone in eCommerce.
With millions of listings across categories like motors, real estate, jobs, and consumer goods, the platform provides a comprehensive view of market trends, consumer preferences, and pricing strategies.
By scraping Subito.it, businesses can access this data in real-time, allowing for more agile and informed decision-making.
For example, if you're an online retailer, you can scrape Subito.it to understand the average pricing of products similar to yours and adjust your pricing strategy accordingly.
Similarly, real estate companies can scrape listings to gauge the market value of properties in different regions.
Data from Subito.it can also be used for sentiment analysis, helping businesses understand what customers are looking for and how they feel about certain products or services.
Use Cases of Scraping Subito.it
- Market Research. Understanding market trends is crucial for any business.
By scraping Subito.it, you can gather data on the most popular products, seasonal trends, and consumer demands, helping you tailor your offerings accordingly.
- Competitive Analysis. Keeping an eye on your competitors is easier than ever with web scraping. Extract data on product listings, customer reviews, and pricing strategies to see how you stack up against the competition.

- Dynamic Pricing. In a fast-paced market, static pricing can be a disadvantage. Scraping Subito.it allows you to monitor real-time pricing trends, enabling you to adjust your prices on the fly to maximize profits or market share.
- Lead Generation. For service-based industries or B2B companies, Subito.it can be a source of potential leads. Scrape contact details and service requests to build a targeted sales funnel.
- Sentiment Analysis. Customer reviews and comments on Subito.it can be scraped for sentiment analysis, providing insights into public opinion and areas for improvement.
Case Studies and Real-World Examples
-
Automotive Dealership. A local car dealership can use Subito.it data to understand the demand for electric cars in their region. By scraping listings and customer inquiries, they can stock up on the most sought-after models, resulting in a 20% increase in sales.
-
Fashion Retailer. A fashion retailer can scrape Subito.it to analyze the popularity of different clothing brands and styles. This data-driven approach allowes for the tailoring of their inventory, leading to a more efficient stock management system and increased sales.
-
Real Estate Firm. A real estate company can scrape Subito.it to gather data on property prices in various neighborhoods. This information can be used to develop a dynamic pricing model that adjusts property prices based on real-time market conditions, significantly optimizing their revenue.
By understanding the importance, use-cases, and real-world applications of scraping Subito.it, it becomes clear that this practice is not just a technical exercise but a strategic necessity for modern businesses.
Ways to Scrape Subito.it
Scraping Subito.it can be approached in multiple ways, each with its own set of advantages and limitations.
Whether you're a coding novice or a seasoned developer, there's a method that will suit your needs.
Manual Scraping
What It Is: Manual scraping is the most straightforward method, requiring no coding skills.
It involves manually visiting the Subito.it website and copying the data you need.
How to Do It:
-
- Open Browser. Navigate to Subito.it on your web browser.
- Search Listings. Use the search bar or category filters to find the listings you're interested in.
- Copy Data. Manually copy and paste the data into a spreadsheet or document.
Pros and Cons:
-
- Pros: Easy to do, no technical skills required.
- Cons: Extremely time-consuming, not practical for large datasets, prone to human error.
Best For: Small-scale projects or quick, one-time data retrieval tasks.
Writing Code
What It Is: This involves writing scripts to automate the scraping process. The most commonly used languages for this are Python and JavaScript.
How to Do It:
-
- Choose a Library. Libraries like BeautifulSoup for Python or Puppeteer for JavaScript are popular choices.
- Inspect Elements. Use your browser's developer tools to inspect the HTML elements containing the data you want.
- Write the Code. Write a script to navigate to Subito.it, locate the data points, and extract them.
- Run the Script. Execute the script to collect the data.
Pros and Cons:
-
- Pros: Highly customizable, can handle large datasets, minimizes human error.
- Cons: Requires coding skills, may require maintenance as website structures change.
Best For: Medium to large-scale projects where customization and scalability are required.
Using Third-Party Scrapers
What It Is: These are pre-built software or platforms designed to scrape data from websites.
How to Do It:
-
- Choose a Scraper. Research and select a third-party scraper that fits your needs.
- Configure. Most of these tools offer a GUI where you can point and click on the data you want to scrape.
- Run the Scraper. Start the scraping process. Some tools offer cloud-based solutions, so you don't have to run the scraper on your machine.
Pros and Cons:
-
- Pros: User-friendly, no coding required, often comes with built-in features like IP rotation.
- Cons: Can be expensive, less customizable than coding your own solution.
Best For: Those who need a more straightforward, less technical way to scrape data at scale.
By understanding these methods, you can choose the one that best fits your project's scope and your technical proficiency. Each has its merits and drawbacks, but all are viable ways to tap into the rich data resources that Subito.it offers.
Tools You'll Need

Writing code is one of the most common ways of scraping Subito.it because it allows for a high degree of customization.
However, coding is just one part of the equation. To scrape a website effectively, you'll need a set of tools that can handle various aspects of the scraping process.
This section provides a general guide on the essential tools you'll need for scraping Subito.it.
Web Scraping Libraries
Web scraping libraries are pre-written code packages that simplify the process of extracting data from websites.
They handle the nitty-gritty details of navigating HTML and HTTP, letting you focus on the data you want.
Python Libraries for Scraping Subito.it:
- Beautiful Soup. Ideal for beginners, Beautiful Soup makes it easy to scrape information from web pages by providing Pythonic idioms for iterating, searching, and modifying the parse tree.
- Scrapy. More suited for large-scale web scraping, Scrapy is an open-source framework that provides all the tools you need to crawl websites and extract data.
- Selenium. While not strictly a web scraping library, Selenium is useful for websites that load data dynamically with JavaScript.
Premium Proxies
Proxies act as intermediaries between your computer and the website you're scraping, masking your IP address. Geonode proxies are known for their efficiency and security.

How Geonode Proxies Can Make Your Scraping More Efficient and Secure:
- IP Rotation. Geonode proxies automatically rotate IP addresses, reducing the risk of being blocked by Subito.it.
- Speed. Geonode offers high-speed proxies that ensure your scraping tasks are completed quickly.
- Security. With Geonode, your data is encrypted, providing an extra layer of security.
Geonode has a dashboard where you can configure your proxy settings. Once configured, you can integrate them into your scraping code.
Essential Browser Extensions
Browser extensions can assist in the web scraping process by helping you understand the structure of a website or by automating some manual tasks.
- Web Scraper: This Chrome extension allows you to configure a plan and scrape data directly from your browser.
- Data Miner: Useful for scraping tables or lists, Data Miner can save you time when you're doing preliminary research.
- Selector Gadget: This extension helps you quickly find CSS selectors, which can be useful when writing your scraping code.
These extensions can be found in the Chrome Web Store. Simply search for the extension and click "Add to Chrome."
By equipping yourself with these essential tools, you're well on your way to scraping Subito.it effectively and efficiently. Whether you're a beginner or an experienced coder, these tools provide the foundation you need to extract valuable data from Subito.it.
Setting Up Your Environment
Before diving into the actual scraping process, it's crucial to set up a conducive environment that supports efficient and effective web scraping. This section serves as a general guide to help you prepare your system for scraping Subito.it.
Installing Required Software
To scrape Subito.it, you'll need a code editor, a Python environment, and specific libraries that facilitate web scraping.
Software Setup for Scraping Subito.it:
-
Code Editor. Choose a code editor where you'll write your scraping script. Popular options include Visual Studio Code, PyCharm, or Jupyter Notebook for more data-centric projects.
-
Python Environment. If you don't already have Python installed, download and install it from the official website. Make sure to install pip (Python's package installer) as well.
-
Web Scraping Libraries: Install the Python libraries you'll use for scraping. Open your terminal and run the following commands:
-
Browser and Driver: If you're using Selenium, you'll also need a web driver that corresponds to your web browser (e.g., ChromeDriver for Google Chrome).
Installation Steps:
- Download your chosen code editor and follow the installation instructions.
- Install Python and make sure to check the box that adds Python to your PATH.
- Open your terminal and run the pip commands to install the web scraping libraries.
- Download the web driver for Selenium and place it in a directory that's on your system's PATH.
Configuring Geonode Proxies
-
Sign Up for Geonode. Visit the Geonode website and sign up for an account. Choose a plan that suits your needs.
-
Access Dashboard. Log in to your Geonode account and navigate to the dashboard.
-
Create a Proxy Pool. In the dashboard, look for the option to create a new proxy pool. Follow the prompts to set up your pool, specifying the countries or cities you want your IP addresses to come from.
-
Get Proxy Details. Once the pool is set up, you'll be given a list of proxy IP addresses and ports. Copy these details.
-
Integrate into Code. In your scraping code, you'll need to configure your web scraping library to route requests through the Geonode proxy. For example, if you're using Python's requests library, you would do something like this: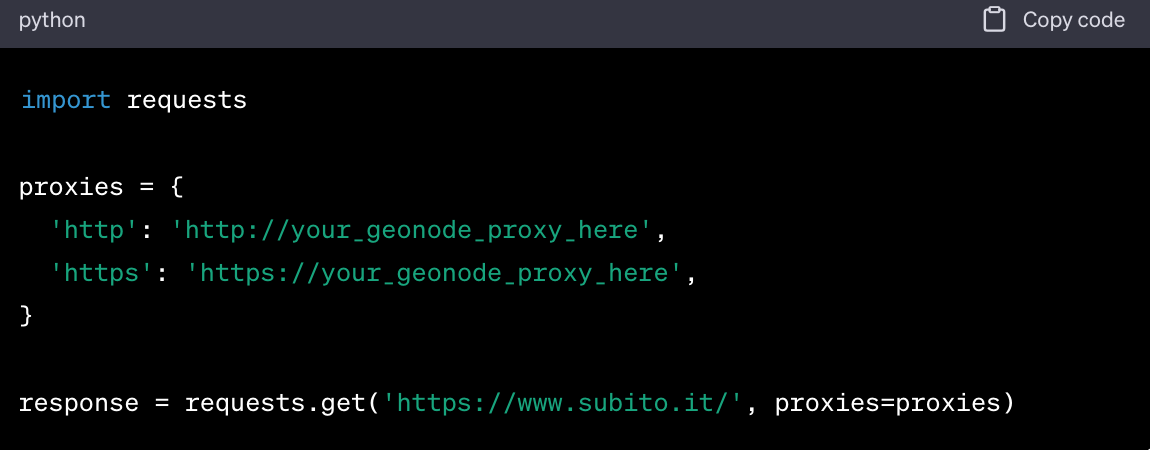
By following these steps, you'll have a robust environment set up for scraping Subito.it. With the right software and proxies in place, you're well-equipped to start gathering the data you need.
The Scraping Process
Once your environment is set up, you're ready to dive into the actual scraping process.
Identifying Data Points
The first step in any web scraping project is to identify exactly what data you want to collect. This could range from product prices and descriptions to user reviews and more.
What Data to Scrape from Subito.it:
- Product Listings. Information such as product name, price, and description.
- Seller Information. Details like seller name, contact information, and ratings.
- User Reviews. Ratings and text reviews from users.
- Search Results. Data from search result pages, including ranking and relevance metrics.
How to Identify this Data:
- Inspect the Website. Navigate through Subito.it and identify the pages that contain the data you're interested in.
- Use Developer Tools. Open your browser's developer tools to inspect the HTML structure and identify the tags that contain your desired data.
Writing the Scraping Code
This involves writing a script in Python (or another language) that will navigate to the web page and extract the data points you've identified.
Here's a simplified Python code snippet using BeautifulSoup to scrape product names and prices from a hypothetical Subito.it page: 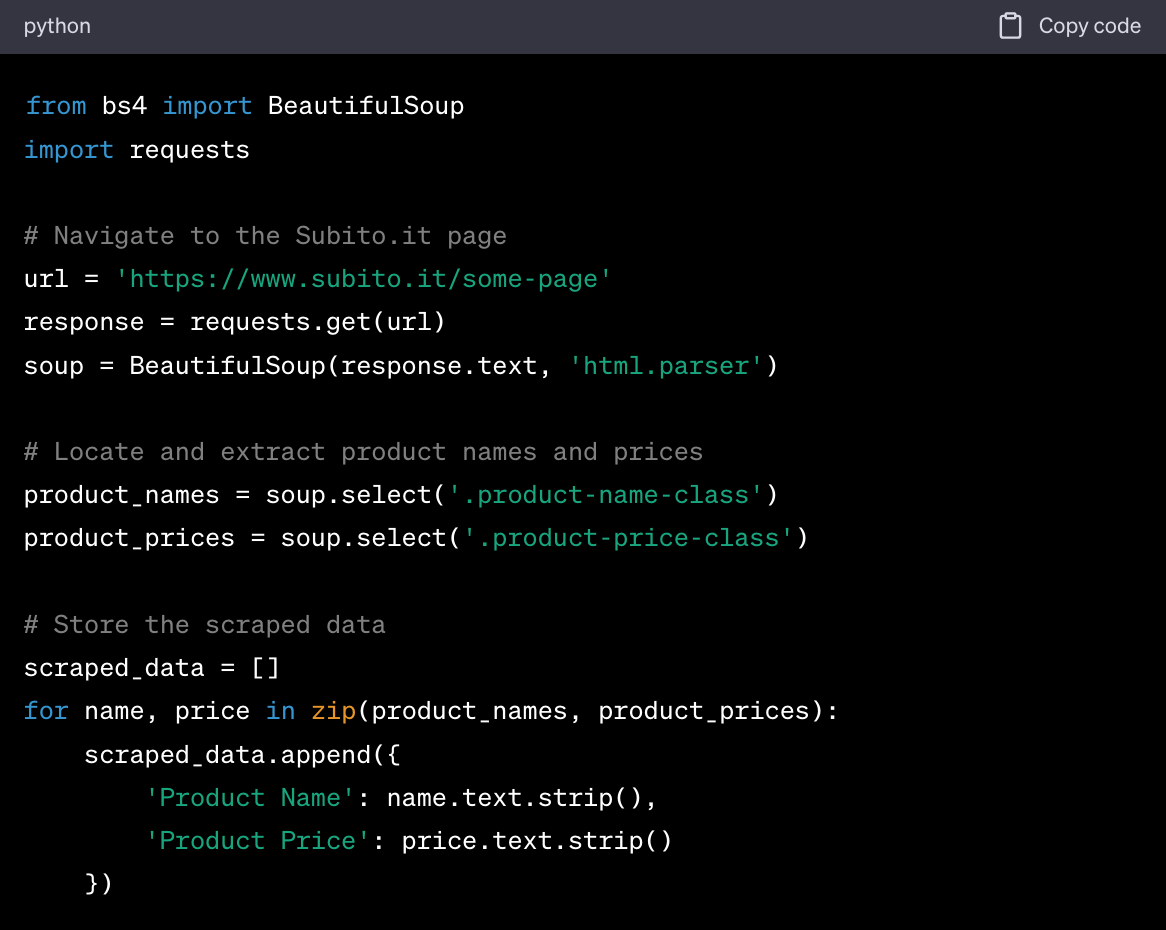
Running the Scraper
This is the stage where you execute your scraping code to collect the data you've targeted.
How to Execute Your Scraping Code and Collect Data
- Test on a Small Scale. Before running your scraper on hundreds of pages, test it on a few to make sure it's working as expected.
- Run the Code. Execute your Python script. This can usually be done directly from your code editor or from the command line by running
python your_script_name.py.
- Monitor the Process. Keep an eye on the script as it runs to ensure there are no errors or issues.
- Store the Data. Make sure your script is set up to store the scraped data in a useful format, such as a CSV file or a database.
By following these steps, you'll be well on your way to successfully scraping valuable data from Subito.it. With the right preparation and execution, web scraping can provide you with the insights you need to make informed decisions.
Best Practices and Legal Considerations

When scraping Subito.it or any other website, it's crucial to be aware of both best practices and legal considerations.
This ensures that your scraping activities are both ethical and compliant with relevant laws and regulations. This section will delve into these aspects in detail.
Respecting Robots.txt
The robots.txt file is a standard used by websites to communicate with web crawlers and other automated agents, indicating which parts of the site should not be processed or scanned.
Ignoring the guidelines set forth in the robots.txt file can lead to your IP address being banned and could potentially result in legal consequences.
Rate Limiting and IP Rotation
Rate limiting is the restriction of the number of requests you can make to a website within a given time frame. IP rotation involves changing your IP address periodically to avoid detection and banning.
How Geonode Proxies Can Help with Rate Limiting and IP Rotation:
- IP Rotation. Geonode proxies automatically rotate your IP address, making it difficult for websites to identify and block you.
- Rate Limiting. Using multiple IP addresses through Geonode allows you to distribute your requests, effectively bypassing rate limits set by the website.
- Configuration. Geonode proxies have settings that allow you to control the frequency and pattern of your requests, helping you to scrape responsibly.
Failing to adhere to rate limits or not rotating IPs can result in your scraper being blocked, rendering your scraping efforts ineffective.
Data Storage and Usage
Once you've scraped the data, how you store and use it is subject to both ethical and legal considerations.
- Storage. Store the data in a secure environment to prevent unauthorized access. Encryption is often recommended.
- Usage. The data you've scraped should be used responsibly. Misusing data for spamming, fraud, or any form of harassment is not only unethical but also illegal.
- Sharing. If you intend to share the scraped data, make sure you have the legal right to do so. Some websites have terms of service that prohibit the sharing of scraped data.
- Attribution. If you're using the data for research or reporting, it's good practice to cite the source.
Improper storage or unethical use of scraped data can lead to legal repercussions and damage to your reputation.
By adhering to these best practices and legal considerations, you can ensure that your web scraping activities are conducted in a responsible and ethical manner. This not only minimizes the risk of legal issues but also contributes to the integrity and reliability of your scraping projects.
Troubleshooting and FAQs
Even with the best preparations, you may encounter issues while scraping Subito.it. This section aims to address common errors and frequently asked questions to help you troubleshoot your scraping activities effectively.
Common Errors and Solutions
Troubleshooting Subito.it Scraping Issues:
-
IP Blocked. If you find that your requests are being denied, it's likely that your IP has been blocked.
- Solution: Use a proxy service like Geonode to rotate your IP addresses.
-
Rate Limit Exceeded. If you're making too many requests in a short period, you may hit the rate limit.
- Solution: Implement a delay between your requests or distribute the requests using multiple IP addresses.
-
Incomplete or Inaccurate Data. Sometimes, the scraper might not collect all the required data or may collect incorrect data.
- Solution: Double-check your code to ensure you're targeting the correct HTML elements.
-
Timeout Errors. Your scraper might time out if a page takes too long to load.
- Solution: Increase the timeout limit in your code or try to optimize your scraper to run faster.
People Also Ask
Frequently Asked Questions and Their Answers:
-
How to Scrape Subito.it Without Getting Blocked?
- Use proxies to rotate your IP addresses and implement rate limiting to avoid making too many requests in a short period. Also, respect the guidelines in Subito.it's
robots.txt file.
-
Is Scraping Subito.it Legal?
- While scraping public data is generally legal, it's crucial to respect the website's terms of service and
robots.txt guidelines. Misusing the scraped data can lead to legal repercussions.
-
How Can I Scrape Subito.it Faster?
- To speed up the scraping process, you can use a more efficient scraping library or framework. Additionally, using a proxy service like Geonode can help distribute your requests across multiple IP addresses, effectively bypassing rate limits.
By being aware of these common issues and FAQs, you can better prepare yourself for the challenges that come with web scraping. Proper troubleshooting can save you time and resources, making your scraping project more efficient and effective.
Wrapping Up
Scraping Subito.it offers a plethora of opportunities for businesses, researchers, and data analysts.
By automating the data collection process, you can gain valuable insights into market trends, consumer behavior, and competitive landscapes.
Whether you're looking to optimize your pricing strategy, understand your target audience, or make data-driven decisions, scraping Subito.it provides you with the raw material you need.
The guide has covered everything from setting up your environment and choosing the right tools to best practices and troubleshooting.
The aim has been to equip you with the knowledge and skills needed to scrape Subito.it effectively and responsibly.
What to Do with the Data You've Scraped and How to Leverage It for Business Success:
-
Data Cleaning:.The first step after scraping is to clean and organize the data. This involves removing duplicates, handling missing values, and converting data types where necessary.
-
Data Analysis. Use statistical methods or machine learning algorithms to analyze the data. This could help you identify patterns, correlations, or trends that could be beneficial for your business.
-
Strategic Implementation. Apply the insights gained from the analysis to your business strategies. For example, if you've scraped pricing data, you could use it to optimize your own pricing strategy.
-
Monitoring and Updating. The web is dynamic, and data can become outdated quickly. Make it a practice to run your scraper periodically to keep your data fresh.
-
Compliance and Ethics. Always ensure that your use of scraped data complies with legal regulations and ethical standards. This includes respecting privacy laws and intellectual property rights.
-
Share Insights. If appropriate, consider sharing your findings with your team, stakeholders, or even the wider community. This not only adds value but also establishes your expertise in the field.
By following these next steps, you can transform the raw data you've scraped into actionable insights, thereby leveraging it for business success.
With the right approach and responsible practices, web scraping can be a powerful tool in your data-driven decision-making arsenal.
