Often termed the "front page of the internet," Reddit is a colossal hub for user-generated content.
With 430 million monthly active users participating in thousands of topic-specific discussions from the latest tech trends to niche hobbies, Reddit is a valuable tool and goldmine of data ready to be tapped into.
But how do you efficiently and ethically extract this data?
In this guide, we delve into understanding Reddit scrapers, the official API, tools, techniques, and best practices to effectively gather Reddit data.
The Significance of Reddit Scraping
Data-driven insights are key to success.
Extracting data from Reddit allows businesses, researchers, and data enthusiasts to comprehend public sentiments, track market trends, and gather user-generated content.
This rich, unstructured data has extensive use cases, such as:
-
Market Research. Reddit's diverse communities, known as "subreddits," cater to almost every conceivable interest. Businesses scrape Reddit posts to gauge consumer sentiments, preferences, and emerging trends in real-time.
-
Product Feedback. Users frequently discuss products and services, offering candid feedback. This invaluable data helps companies refine their offerings and address concerns.
-
Competitive Analysis. By monitoring discussions about competitors, businesses can identify strengths, weaknesses, and opportunities in the market.
-
Content Ideas. Content creators and marketers use Reddit to discover hot posts and trending topics, ensuring their content remains relevant and engaging.
-
Academic Research. Researchers tap into Reddit's vast data pool to study online behaviors, cultural trends, and social dynamics.
-
Crisis Management. Brands can detect potential PR crises early by monitoring negative sentiments or controversies on Reddit.
-
Data Training Sets. For those in AI and machine learning, Reddit provides vast datasets for training models, especially in natural language processing.
Understanding the Structure of Reddit for Effective Web Scraping
Reddit is a complex platform with a unique structure that distinguishes it from other social media platforms.
Grasping this structure is paramount for anyone aiming to scrape data from Reddit, as it ensures the extraction of relevant and comprehensive information.
Here's an in-depth exploration:
-
Subreddits. These are community-centric sections dedicated to specific topics or interests.
Each subreddit has its unique URL, often denoted as "r/[subreddit_name]".
For instance, there are "deals subreddits" that focus on promotions and discounts.
Knowing the structure of subreddit URLs is essential for targeting specific communities.
-
Posts. Users can submit posts within subreddits. Posts can range from in-depth blog posts to images, videos, or links to external sites.
Each post has its unique structure, often referred to as the post dictionary, which includes details like the post author, post titles, and the current post content.
-
Comments. Each individual post can have comments from posts, leading to nested discussions.
Understanding the average comments per post or targeting comment-heavy posts can provide richer data for analysis.
-
User Profiles and App Users. Every Reddit user, whether they use the Reddit App or browser, has a profile that displays their activity, including posts and comments.
This is a goldmine for data, especially for analyzing user behavior.
-
Digital Products and App Purchases. Reddit offers various digital products distribution options, including awards and Reddit Premium.
Understanding how users interact with these, especially through app purchases can offer insights into user spending behavior.
-
App Advertising. Reddit provides advertising opportunities that allow brands to reach specific demographics or subreddit communities.
This is a vital tool for businesses looking to advertise on the platform.
-
Browser Interactions. Whether users access Reddit through a browser session or use browser extensions, each interaction leaves behind data.
Knowing how to scrape browser interactions and browser profiles can provide deeper insights into user behavior.
-
Cloud and Deployment. Reddit uses cloud service solutions, and understanding this can be crucial, especially when considering the cloud during deployment.
-
Analysis and Tools. With the right analysis tools, businesses can decipher how a topic addresses across dozens of communities or how users interact with the upvote button or the upvote element.
-
Automation and AI. Modern social media scrapers come equipped with automation features. Some even use generative AI tools to predict user behavior or to generate content.
-
Ethical Considerations. When scraping, it's essential to respect the respective owners of content and ensure that descriptive user agents are used to avoid misrepresentation.
Always aim for the the correct target URL to extract the target info you need without infringing on user rights.
- Additional Elements. Reddit is vast, and there are other elements like the subreddit dictionary, description fields, and more that can be targeted for more detailed data.
Reddit's multifaceted structure is a playground for web scrapers. To extract meaningful data, one must understand its intricacies.
Whether you're analyzing comments from subreddits, studying code lines for patterns, or exploring how products are marketed, knowing Reddit's structure ensures that your scraping endeavors are both efficient and ethical.
Scraper Tool 1: The Official Reddit API
Some people perceive Reddit as merely another social media platform. However, its unique structure and democratic voting system make it much more.
Reddit thrives on user-generated content segregated into niche communities known as "subreddits."
Each subreddit covers a specific topic, allowing users to engage in discussions, share resources, and seek advice.
The most upvoted content — the most popular posts — rise to the top, turning Reddit into a real-time reflection of public interest and sentiment.
Reddit API Overview and Terms
Reddit's official DATA API is a powerful tool that provides structured access to the platform's vast content.
It is an essential tool for developers, researchers, and businesses aiming to tap into the rich insights available on the platform.
The API allows third-party developers to read comments, fetch user information, access subreddit details, and much more in a manner that's both efficient and in line with Reddit's guidelines.
Usage Guidelines, Limitations and Restrictions
- Registration & Eligibility. Before accessing the Data API, users must register and ensure they meet the eligibility criteria. This includes being of legal age and not being barred from using the API under any applicable laws.
- License. Reddit grants a non-exclusive, non-transferable, revocable license to access and use the Data API. This means users can't sublicense or transfer their API access rights to another party.
- User Content. While the content on Reddit is user-generated, the API provides a way to access this content without modifying it. Any use of user content must respect the rights of the original content creators.
- Privacy & Data Handling. Developers must disclose how they handle data collected via the API, ensuring transparency and compliance with privacy laws.
- API Limitations. Reddit may impose limits on API usage, such as the number of requests per hour. It's crucial to be aware of and respect these limits to avoid disruptions.
- Fees & Commercial Use. While the API is generally free for basic use, Reddit reserves the right to charge for higher usage levels or commercial purposes.
- Compliance. Users of the API must comply with Reddit's User Agreement, Privacy Policy, and any other relevant terms. This ensures that data access remains ethical and in line with Reddit's community standards.
Understanding and adhering to these terms is crucial for anyone looking to use Reddit's data in their applications or research. It ensures a smooth, uninterrupted data access experience while maintaining the integrity and ethos of the Reddit community.
Scraper Tool 2: Python and Selenium
Python is a widely-used programming language known for its simplicity and versatility.
Python offers a plethora of libraries and frameworks that make scraping more manageable. One such tool is Selenium, originally designed for web testing but has since become a go-to for web scraping tasks.
Selenium works by automating web browsers. It can simulate human-like browsing behavior, making it possible to scrape web pages as if a real user is navigating them.
When paired with Python, Selenium allows developers to write scripts that can perform tasks like logging into accounts, navigating to specific pages, clicking buttons, and, most importantly, extracting data.
For platforms like Reddit, which are rich in dynamic content (content that's loaded or changed without the page being refreshed), Selenium proves invaluable.
Traditional scraping tools might struggle with such content, but Selenium, being a browser automation tool, can easily access it.
Benefits of Using Python and Selenium for Reddit Scraping
- Dynamic Content Access. As mentioned, Selenium can interact with dynamic content, ensuring no data is missed during the scraping process.
- Human-like Interactions. Selenium's ability to mimic human interactions, like scrolling or clicking, can help bypass some anti-scraping measures.
- Flexibility. Python's extensive libraries and Selenium's browser automation capabilities is a flexible combination. Whether it's handling cookies, managing sessions, or dealing with pop-ups, Python and Selenium can handle it all.
- Broad Browser Support. Selenium supports multiple browsers, including Chrome, Firefox, and Safari, allowing for cross-browser scraping if needed.
Potential Challenges
-
Performance. Since Selenium automates a real browser, it can be slower than other lightweight scraping tools that directly fetch page source code.
-
Complexity. Setting up a Selenium-based scraper might be more complex than using simple HTTP request-based tools, especially for beginners.
-
Anti-scraping Measures. While Selenium can bypass some anti-scraping techniques, platforms like Reddit are continually evolving their defenses. This means scrapers might face challenges like CAPTCHAs, rate limits, or temporary IP bans.
-
Maintenance. Web pages change over time. If Reddit undergoes a design overhaul or changes its structure, the scraper might break and require updates.
Scraper Tool 3: PRAW (Python Reddit API Wrapper)
PRAW, which stands for Python Reddit API Wrapper, is essentially a bridge between Python applications and Reddit's API.
Instead of dealing with raw HTTP requests and parsing through intricate JSON responses, developers can use PRAW's intuitive methods to fetch and interact with Reddit data.
Advantages of using PRAW
-
Simplicity. PRAW abstracts the complexities of the Reddit API, offering developers straightforward methods to access data.
For instance, fetching the top posts from a subreddit or retrieving comments from a specific thread becomes a task of just a few lines of code.
-
Rate Limit Handling. Reddit imposes restrictions on how frequently its API can be accessed.
PRAW automatically manages these rate limits, ensuring your application doesn't exceed them and risk temporary bans.
-
Compliance. By using PRAW, developers inherently adhere to Reddit's API terms of service, minimizing the risk of data access issues.
-
Extensive Documentation. PRAW comes with comprehensive documentation, making it easier for both beginners and experienced developers to get started and troubleshoot issues.
-
Active Community. PRAW has an active community. This means regular updates, a plethora of online resources, and community support for any challenges faced.
Basic Setup and Usage Examples
Setup
-
Before using PRAW, register a script application on Reddit's developer portal to obtain the necessary API credentials.
-
Install PRAW via pip.

- Initialize the Reddit instance with your API credentials.
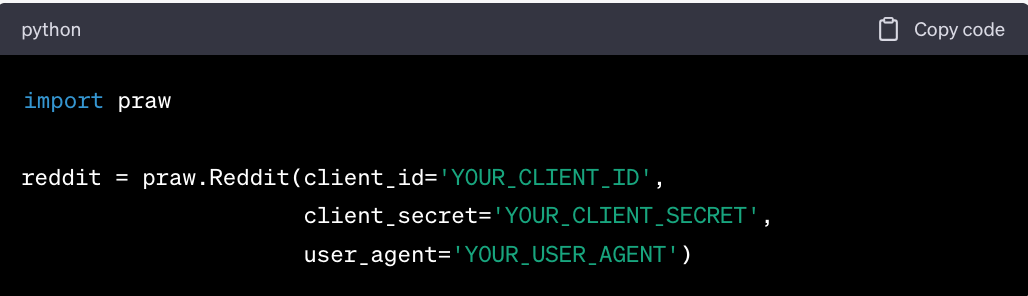
Usage Examples
- Extracting the top 10 subreddit posts

- Retrieving comments from a specific thread
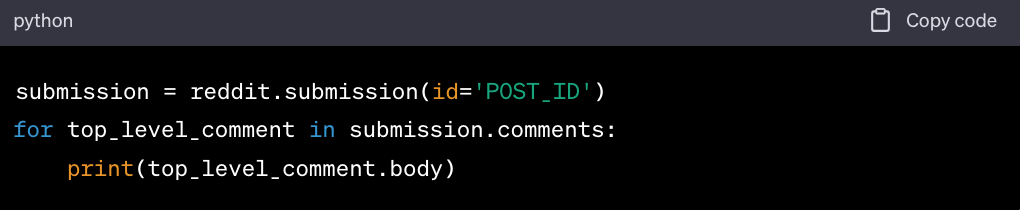
- Searching for posts containing a keyword

PRAW is a must-have tool for anyone looking to delve into Reddit data using Python. Its simplicity, combined with its power, makes it an ideal choice for projects ranging from simple data extraction tasks to complex data analysis endeavors.
Scraper Tool 4: The Scrapy Framework
Scrapy is a high-level, open-source web crawling and scraping framework written in Python. It's designed to handle a wide range of scraping tasks, from simple one-off data extractions to large-scale, complex web crawling projects. Scrapy is not just limited to Reddit but can be used for scraping data from any website.
Key Features
-
Versatility. Scrapy can extract data from websites using CSS selectors, XPath, or even regular expressions, catering to various website structures.
-
Middleware and Extensions. Scrapy supports middlewares and extensions, allowing developers to customize the scraping process, handle retries, user agents, and even integrate proxy pools.
-
Pipelining. Once data is scraped, Scrapy offers item pipelines to process, validate, and store the data. This can be in databases, files, or even cloud storage.
-
Concurrent Crawling. Scrapy is built on the Twisted asynchronous networking library, enabling it to handle multiple requests concurrently, speeding up the data extraction process.
-
Robust Error Handling. Scrapy can handle errors gracefully, ensuring that a minor hiccup doesn't halt the entire scraping process.
-
Built-in Exporters. Scrapy can export results in multiple formats like JSON, CSV, and XML without requiring additional plugins or tools.
How to Set Up and Use Scrapy for Reddit Data Extraction
Setting up Scrapy: Step-by-Step Tutorial
-
Install Scrapy using pip
-
Start a new Scrapy project 
Using Scrapy for Reddit Data Extraction
-
Create a Spider. Within your Scrapy project, you'll create spiders, which are classes that define how to follow links and extract data. For Reddit, you might create a spider like this: 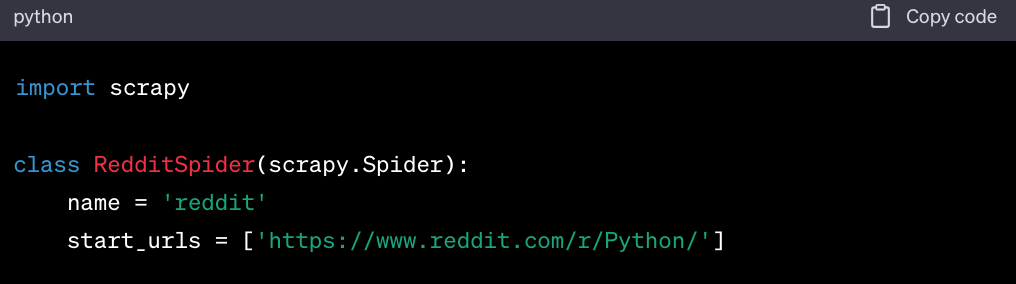
-
Define Extraction Logic. Use CSS selectors or XPath to extract data from the Reddit page. 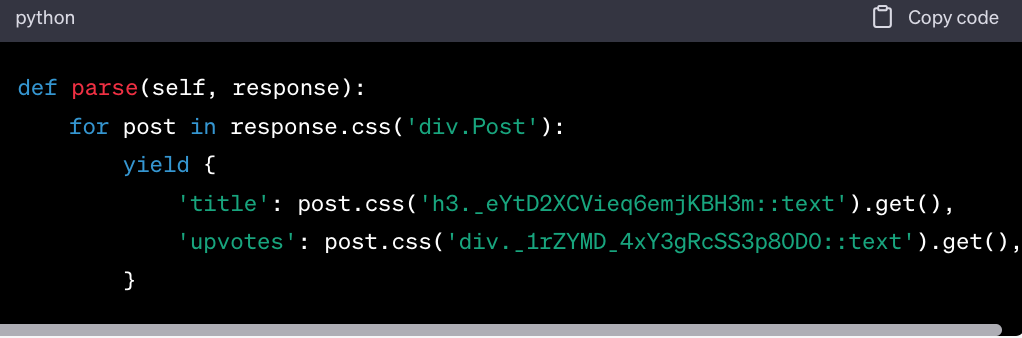
-
Follow Pagination. Reddit has multiple pages of content. Scrapy can be set up to follow links and scrape data across different pages.
-
Run the Spider: Once your spider is set up, navigate to the project directory and run: 
-
Storing Data: Scrapy can store the scraped data in various formats. For instance, to store the data in a JSON file: 
Scraper Tool 5: GitHub Repositories
GitHub, the world's leading software development platform, hosts a plethora of repositories dedicated to various tasks, including web scraping.
Among these, numerous repositories focus specifically on scraping Reddit data.
These repositories often provide pre-built tools, scripts, or libraries that can simplify the Reddit scraping process and make it accessible even to those with limited coding experience.
Advantages of Using GitHub Repositories for Reddit Scraping
-
Ready-to-Use Solutions. Many GitHub repositories offer complete solutions that require minimal setup. Users can clone the repository, follow the provided instructions, and start scraping without having to build a tool from scratch.
-
Community Support. Popular repositories often have active communities. Users can raise issues, seek help, or even contribute to the project, enhancing the tool's capabilities.
-
Continuous Updates. Given the dynamic nature of websites, scraping tools need regular updates. Active GitHub repositories are frequently updated to address changes in the target website's structure or to improve functionality.
-
Diverse Approaches. Different repositories might employ various techniques or tools for scraping, from Python-based solutions like PRAW or Scrapy to Node.js or even Dockerized applications. This diversity allows users to choose a tool that aligns with their technical expertise and project requirements.
-
Documentation and Examples. Most reputable repositories provide comprehensive documentation, setup guides, and usage examples, ensuring users can get up and running without hurdles.
Exploring GitHub for Reddit Scrapers
A simple search on GitHub with the topic "reddit-scraper" reveals a range of repositories tailored for Reddit data extraction.
Some potential repositories you might find include:
-
Reddit Scraper Bots. These are automated scripts that can fetch posts, comments, and more from specified subreddits or threads.
-
Reddit API Wrappers. While PRAW is the most popular, other wrappers might offer unique features or cater to different programming languages.
-
Dockerized Reddit Scrapers. For those looking for containerized solutions, some repositories provide Docker setups to ensure consistent and scalable scraping operations.
-
Specialized Tools. Some Reddit crawler tools might focus on specific tasks, like downloading all images from a subreddit, extracting trending topics, or monitoring specific keywords.
Steps in Using a GitHub Repository for Reddit Scraping
-
Choose a Repository. Navigate to the reddit-scraper topic on GitHub and select a repository that aligns with your needs.
-
Clone and Setup. Follow the repository's instructions, which typically involve cloning the repository and setting up any required dependencies.
-
Configure. Many tools will require some configuration, such as specifying the target subreddit, setting up API keys, or defining output formats.
-
Run and Extract Data. Execute the provided scripts or commands to start the scraping process.
-
Post-Processing. Depending on the tool, you might need to process the extracted data further, such as filtering, cleaning, or converting to a desired format.
Scraper Tool 6: Third-Party Reddit Scrapers
The vastness and richness of data on Reddit have led to the rise of several third-party scraping tools. These tools aim to simplify the scraping process, making it accessible to a broader audience, from businesses to researchers. Let's delve into some of the most popular third-party Reddit scrapers:
- Pricing Model: Offers a flexible pay-as-you-go model.
- User Experience: Intuitive interface suitable for both beginners and experts.
- Performance: Fast and reliable data extraction.
- Privacy: Emphasizes user privacy, ensuring data integrity and security.
- Automation: Features AI-driven automation for adaptive scraping.
- Data Transformation: Integrated tools for refining and analyzing scraped data.
- Versatility: Comprehensive scraping solution targeting multiple websites.
- Interface: Visual interface for easy project design.
- Advanced Features: Handles AJAX and JavaScript for thorough data extraction.
- Scheduling: Offers capabilities for setting up recurring scraping tasks.
- Deployment: Provides both cloud-based and local extraction options.
- User-Friendly: Easy setup with capabilities to handle CAPTCHAs and IP bans.
- Integration: Features API integration for seamless data transfer.
- Simplicity: Focuses on providing pre-built modules for easy scraping.
- Affordability: Emphasizes cost-effective solutions suitable for various budgets.
- Primary Service: Known as a proxy provider with scraping insights.
- Anonymity: Offers rotating IPs and a vast pool of residential proxies for anonymous scraping.
- Guidance: Provides detailed guides on web scraping, including Reddit.
- API-Based Approach: Offers a straightforward API for easy integration into existing systems.
- Scalability: Designed to handle large-scale scraping tasks without compromising speed.
- Anonymity: Uses a rotating proxy system to ensure anonymous and uninterrupted scraping.
- Versatility: Supports multiple platforms, with Reddit being one of its specialties.
While each third-party scraper brings its unique strengths to the table, Geonode's user-centric approach and flexible pricing make it a standout option.
However, the best tool often depends on individual requirements, technical expertise, and budget.
Best Practices and Ethical Considerations
Reddit scraping, while a potent tool for data extraction, comes with its own set of responsibilities.
Ensuring ethical practices not only protects the rights of users but also ensures the longevity and reputation of your scraping endeavors.
Here's a deep dive into the best practices and ethical considerations when scraping Reddit:
Respecting User Privacy
The digital age has brought about heightened concerns regarding user privacy. When scraping Reddit, it's crucial to prioritize the privacy of the platform's users.
-
Ethical Scraping. Always ensure that the data you're extracting is publicly available. Avoid scraping personal information or content from private subreddits. Remember, just because data is accessible doesn't mean it's ethical to scrape.
-
Anonymity. While Reddit users operate under pseudonyms, it's essential to treat this data with care. Avoid actions that could de-anonymize users or reveal their real-world identities.
-
Data Protection. If storing scraped data, ensure it's encrypted and stored securely. Implement robust cybersecurity measures to prevent unauthorized access.
-
Transparency. If you're using scraped data for research or business purposes, be transparent about your data sources and how the data will be used.
Handling Rate Limits and Restrictions
Reddit, like many platforms, implements rate limits to ensure server stability and prevent misuse.
-
Understand API limits. If using Reddit's API, familiarize yourself with its rate limits. Typically, these are set at a certain number of requests per minute. Exceeding these limits can result in temporary or permanent bans.
-
Use delays. Introduce delays between scraping requests. This not only respects the platform's servers but also reduces the chances of your scraper being identified and blocked.
-
Rotate IPs and user-agents with a reliable proxy service provider. Using Geonode's residential proxies can help bypass restrictions by providing a rotating pool of IP addresses, making your scraping activities appear more organic. Coupled with rotating user-agents, this strategy can significantly reduce the chances of being blocked. However, always use this strategy ethically and avoid aggressive scraping that disrupts the platform.
-
Respect Reddit's robots.txt. The robots.txt file provides guidelines on what can and cannot be scraped. Always check and adhere to Reddit's rules.
Data Storage and Usage
The responsibility doesn't end after scraping data. How you store and use this data is also crucial.
-
Secure Storage. Ensure that any stored data is kept in encrypted databases. Regularly back up this data and implement security measures to prevent breaches.
-
Data Minimization. Only store data that's necessary for your purpose. Avoid hoarding excessive amounts of information, especially if it's sensitive or personal.
-
Ethical Usage. If you're publishing or sharing scraped data, ensure it doesn't harm or misrepresent the Reddit community.
Always seek consent if using data in ways that might affect users or their reputations.
-
Stay Updated: Reddit's terms of service and community guidelines can change. Regularly review these to ensure your scraping practices remain compliant.
While Reddit scraping offers vast opportunities for data extraction, it's paramount to approach it with respect and responsibility.
Leveraging tools like Geonode's residential proxies can enhance your scraping capabilities, but ethical considerations should always be at the forefront of any scraping project, ensuring that the rights of users and the platform are always upheld.
People Also Ask
Q: What is the difference between using the official Reddit API and third-party scrapers?
A: The official Reddit API is provided by Reddit and has specific rate limits and terms of use. Third-party scrapers might offer more flexibility but may not always adhere to Reddit's guidelines.
Q: How can I ensure I'm scraping Reddit ethically and legally?
A: Always respect user privacy, adhere to Reddit's terms of service, and avoid scraping private or sensitive information.
Q: Are there any costs associated with using the Reddit API?
A: While basic access is free, there might be costs for higher request volumes or premium features.
Q: How can I handle rate limits and avoid getting banned?
A: Introduce delays between requests, respect Reddit's robots.txt, and consider using rotating proxies.
Q: What are the best tools for scraping Reddit comments and other data?
A: Popular tools include Geonode, Parsehub, and Octoparse, but the best tool depends on individual needs and expertise.
Taking The First Step Towards Reddit Scraping
Reddit scraping may seem daunting at first, especially with the multitude of tools and techniques at your disposal.
However, remember that every expert was once a beginner. The key is to start small and gradually scale up as you gain confidence and understanding.
Whether you're a researcher seeking insights, a marketer tracking trends, or a curious data enthusiast, scraping Reddit can unlock a wealth of information. It's a skill that truly embodies the saying, "In the realm of coding, the possibilities are endless."
So, roll up your sleeves and embark on your Reddit scraping journey today. Embrace the challenges and remember that each hurdle is a stepping stone towards mastery.
